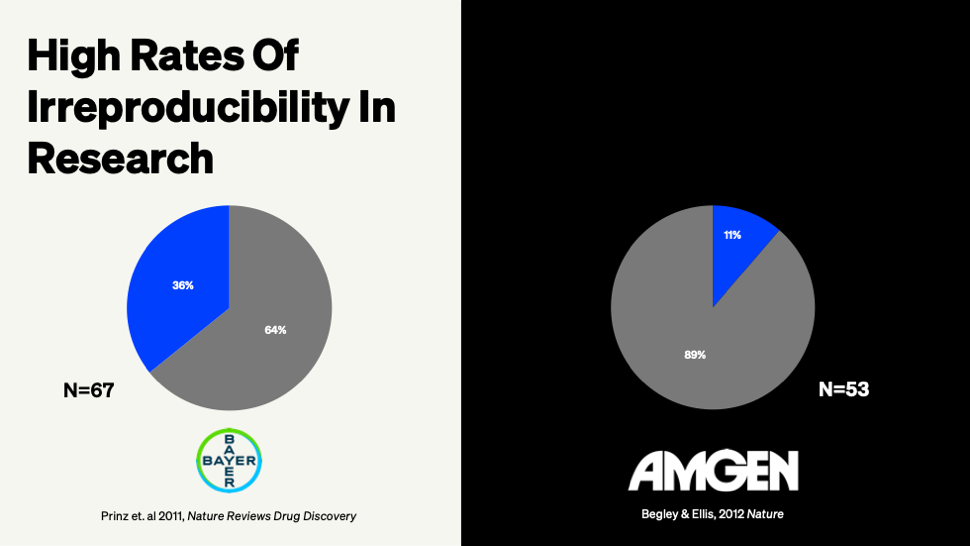
89% percent. That's how many landmark cancer studies Amgen researchers couldn't replicate when they tried.
Not papers from questionable journals or obscure labs. We're talking about the high-impact publications your teams rely on for target validation and mechanism-of-action decisions. Out of 53 major studies, only six held up under scrutiny.
If you're running R&D at a pharmaceutical company or biotech firm, there's a good chance your team is building on research that's just as shaky.
When The Data Makes You Rethink Everything
Amgen's reproducibility effort wasn't some half-hearted literature review. These researchers spent over a decade and millions of dollars trying to validate findings before moving compounds into development. They were financially incentivized to make things work. Still, they could only confirm 11% of what they tested.
Bayer ran similar experiments and got 36% reproducibility. The math is stark. If your manufacturing process had a 36% success rate, you'd be shut down by Friday. Yet we're routinely making go/no-go decisions at stage gates based on literature that fails to replicate more often than it succeeds.
A single Phase III clinical trial costs upwards of $2 billion and takes a decade to complete. Building on shaky foundational research becomes a potential company-killer. The problem extends well beyond oncology. CNS drug development has even worse reproducibility rates. Rare disease research often builds on single-lab findings that nobody's ever attempted to validate.
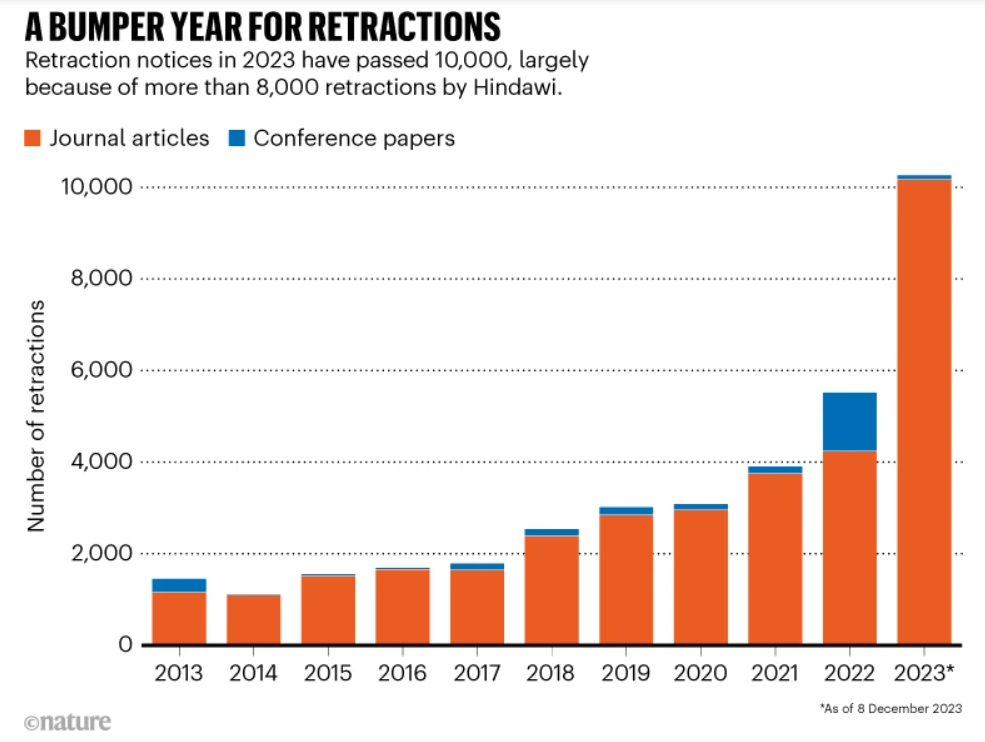
Retractions have jumped from about 1,000 in 2013 to over 10,000 in 2023. Those are just the papers that get formally retracted. All the problematic research still out there, quietly misleading teams, never shows up in these numbers.
Drug Development's Backward Economics Problem
Moore's Law, the principle that computing power doubles while costs halve every couple years, spelled backward gives us Eroom's Law. Drug development follows the opposite trajectory: exponentially rising costs, longer timelines, and declining efficiency.
Part of it's regulation. Part of it's that we've picked the low-hanging fruit. But there's another factor: when you can't trust foundational research, every new program starts from square one. You've got to re-validate everything yourself. Every mechanism, every target, every pathway.
Your competitors are doing the same thing. Everyone's duplicating the same validation work because nobody trusts anyone else's data. This hits your bottom line directly. But it also complicates portfolio reviews, undermines scientific advisory board meetings, and forces more extensive regulatory submissions because the FDA has seen the same reproducibility studies everyone else has.
Then ChatGPT Showed Up
AI arrived to complicate things further. What can be done with this technology is extraordinary, but it creates a new problem: AI-generated citations that look real but correspond to papers that don't exist.
Librarians now field regular requests for phantom papers. The citations look so real that people don't question them until they try to pull the full text. Literature reviews are making it into portfolio meetings with AI-hallucinated citations mixed in among real ones, all going undetected.
This layers on top of existing problems with paper mills, which have gotten sophisticated enough to fool traditional screening methods. For corporate researchers making million-dollar decisions based on literature reviews, the ground has shifted.
Let's Talk About What's Really Driving This
The incentive structure in academic research creates some challenging dynamics. Researchers get evaluated and funded based largely on where they publish. High-impact journals get their status from citation counts. The system ties career advancement, grant funding, and institutional support to these metrics.
There's even a principle: CREAM (Citations Rule Everything Around Me). Academia has a sense of humor about its dysfunction.
The problem isn't that researchers don't care about rigorous science. Most do. But the system rewards publication metrics in ways that can pull against the slow, careful work of validation and replication. Citation counts treat every citation as equal. Whether a paper's being cited because it provides rock-solid supporting evidence, or because it's being debunked, or because someone mentioned it in passing, they all count the same toward impact metrics.
Flashy, novel results get published and cited more readily than rigorous replication studies. Papers that confirm popular theories get more traction than papers that challenge them, even when the challenging work might be more scientifically valuable.
When the system measures success primarily through citation counts, researchers have to optimize for those metrics to survive in their careers. That's not a character flaw. It's a structural problem with downstream effects on everyone who depends on published research, including every drug development team trying to make smart decisions about resource allocation.
There's Actually A Way Out Of This Mess
Some genuinely good news: smart people have figured out that not all citations are created equal, and we finally have the technology to distinguish between them at scale.
The core insight is simple: context matters.
Instead of counting citations, we can now examine why and how papers are being cited. Is this study being referenced because five independent labs confirmed its findings? Is it being used as an example of flawed methodology? Is it being actively challenged by contradictory evidence?
Eugene Garfield proposed this in the 1960s when he created the first citation index. He recognized that citations needed "markers" to indicate relationships between papers. The technology to implement his vision didn't exist yet. Now it does.

By analyzing full text of papers, not only counting backward links, we can classify citations as supporting, contrasting, or mentioning the cited work. This fundamentally changes how you evaluate literature.
It's the difference between knowing a paper has 500 citations and knowing that 300 support its findings while 150 challenge them.
That distinction matters whether you're doing due diligence on a licensing deal, making go/no-go decisions at stage gates, or running portfolio reviews. The same technology that's creating problems with AI-generated citations can also be part of the solution when it's properly grounded in verified research.
The Strategic Edge In A Trust Crisis
The research integrity crisis creates genuine competitive advantage for organizations that adapt quickly.
Most competitors are still making decisions based on citation counts and journal impact factors. They're building on research foundations that may or may not be solid. Their due diligence processes catch obvious problems but miss subtler issues.
Organizations with better tools for literature evaluation can move differently. Literature reviews that automatically flag questionable research mean fewer false starts. Due diligence that catches problems others miss means better licensing deals. Portfolio reviews grounded in independently validated research mean smarter resource allocation.
The companies adopting these tools early gain compounding advantages: fewer false starts, faster decisions, smarter risk-taking, and more efficient paths from discovery to market.
Appropriate skepticism and systems that separate signal from noise become competitive necessities, not cynical overreaction. The volume of scientific literature is only going to increase; the number of bad actors and honest mistakes will increase too. The organizations that thrive will be those with better tools for taking this on.
Integrating Better Research Evaluation Into Your Process
The research trust crisis isn't going away. As AI gets more sophisticated, distinguishing reliable research from sophisticated counterfeits will get harder. Paper mills are becoming more sophisticated. Academic incentive structures aren't changing.
What can change is how your organization responds.
You've got sophisticated processes for validating your own experimental data. Quality control, replication requirements, statistical thresholds. The same rigor should apply to external research you're building upon. But most organizations don't have systematic processes for this. Literature evaluation happens informally, inconsistently, often by the most junior people because it's seen as grunt work.

The tools exist now to change that. Context-aware citation analysis shows you how papers are being cited, not just how often. AI research assistants grounded in peer-reviewed literature let your researchers ask complex questions in natural language and get synthesized answers backed by verifiable citations. Instead of spending three days reading papers to understand off-target effects of a specific inhibitor class, you get an evidence-based answer with citations to primary literature that you can verify. The key difference from tools like ChatGPT: when these research-focused AI assistants don't know something, they say so rather than making something up. Automated screening catches retracted papers and flags problematic research your team might otherwise miss.
These are production-ready technologies being used by leading organizations right now.
Here's a concrete challenge: take a random sample of 20 highly-cited papers your teams referenced in the last year. Run them through systematic evaluation. How many have been formally retracted? How many have been challenged by subsequent research? How many have been independently validated?
The answers usually surprise people. Most organizations discover their literature databases contain higher rates of problematic research than expected. Single-lab findings treated as established fact. Papers with failed replications that nobody noticed. Research that's been quietly questioned but never formally retracted.
Understanding what you're currently working with is step one. The companies building systems to answer these questions systematically will be leading their fields in five years. The ones who aren't will keep wondering why drug development keeps getting more expensive while their competitors move faster and make smarter bets.
The reproducibility crisis won't fix itself overnight. But the tools to address it exist now, and organizations that adopt them early will both protect their own programs and contribute to broader change in how research gets evaluated.